












В современном мире, где огромные объемы данных создаются и обрабатываются ежедневно, становится все более важной задача сохранения и обеспечения доступа к этой информации. Большие компании, сетевые платформы и сервисы, зависящие от уверенного хранения данных, обращаются к распределенным системам хранения данных, которые обеспечивают эффективность и надежность работы.
Распределенные системы хранения данных представляют собой сеть серверов и устройств, которые совместно обрабатывают и хранят данные. Они позволяют распределить нагрузку и обеспечить работу системы на высоком уровне производительности. Кроме того, эти системы устойчивы к отказам и сбоям, так как данные дублируются и хранятся на нескольких устройствах и серверах одновременно.
Эффективность распределенных систем хранения данных обеспечивается за счет их горизонтальной масштабируемости. Фрагментирование данных позволяет распределить нагрузку равномерно между серверами, что позволяет обрабатывать большие объемы информации. Кроме того, процессы репликации и параллельного выполнения запросов позволяют ускорить обработку данных и снизить задержки.
Надежность распределенных систем хранения данных определяется их архитектурой и механизмами обнаружения и восстановления отказов. При возникновении сбоев, данные автоматически реплицируются на другие устройства, что обеспечивает их сохранность. Кроме того, система имеет механизмы детектирования и автоматического восстановления отказов, что позволяет минимизировать время простоя и обеспечить непрерывную работу системы.
Распределение данных
Один из ключевых аспектов распределенных систем хранения данных заключается в распределении самих данных. Распределение данных позволяет эффективно управлять большим объемом информации и обеспечить высокую доступность данных.
При распределении данных они разбиваются на более мелкие фрагменты, которые хранятся на различных узлах системы. Каждый фрагмент данных имеет свой уникальный идентификатор (ключ), который используется для определения его расположения и быстрого доступа к нему.
Распределение данных позволяет достичь баланса нагрузки между узлами системы и обеспечить параллельную обработку запросов. В результате, система может обрабатывать большое количество запросов одновременно и обеспечивать высокую производительность.
При распределении данных также учитывается их репликация. Репликация данных позволяет создать копии фрагментов данных на разных узлах системы. Это обеспечивает высокую надежность и отказоустойчивость системы, так как при сбое одной ноды данные могут быть доступны с других нод.
Распределение данных может осуществляться по различным стратегиям, в зависимости от требований к системе. Например, данные могут быть распределены по хэшу ключа, по диапазону ключей, по репликации на узлы с определенными характеристиками и т. д. Выбор стратегии распределения данных зависит от конкретной задачи и требований к системе.
Важно отметить, что распределение данных требует хорошей организации и балансировки нагрузки между узлами системы. Неправильное распределение данных может привести к перегрузке некоторых узлов и снижению производительности системы в целом. Поэтому необходимо тщательно планировать и мониторить распределение данных в распределенных системах хранения данных.
Итог: распределение данных является важным аспектом архитектуры распределенных систем хранения данных. Оно позволяет обеспечить высокую производительность, надежность и масштабируемость системы. При выборе стратегии распределения данных необходимо учитывать требования к системе и хорошо организовывать балансировку нагрузки между узлами системы.
Архитектура системы
Архитектура распределенной системы хранения данных представляет собой основу ее функционирования. Она определяет способы организации и взаимодействия между различными компонентами системы, такими как серверы, клиенты и сетевые устройства. Корректное проектирование архитектуры системы позволяет обеспечить ее эффективность и надежность.
Одной из основных задач, которые решает архитектура распределенной системы, является обеспечение масштабируемости. Это означает, что система способна управлять и обрабатывать большие объемы данных и одновременно обеспечивать потребности множества пользователей. Для достижения этой цели применяются различные подходы, такие как горизонтальное и вертикальное масштабирование.
Распределение данных
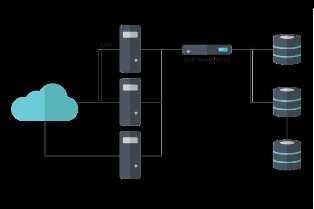
Распределение данных является важным аспектом архитектуры распределенных систем хранения данных. Оно позволяет эффективно организовать доступ к информации и обеспечить балансировку нагрузки между серверами. Для распределения данных применяются различные алгоритмы и стратегии, включая горизонтальное и вертикальное фрагментирование.
Горизонтальное фрагментирование предполагает разделение данных на несколько независимых частей и их хранение на разных серверах. Это позволяет увеличить пропускную способность системы и обеспечить более равномерную загрузку серверов. Вертикальное фрагментирование, в свою очередь, предполагает разделение данных по видам и хранение каждого вида на отдельном сервере.
Применение распределенных систем
Распределенные системы хранения данных нашли широкое применение в различных областях. Они используются в сфере банковского дела для хранения и обработки финансовых данных, в интернет-коммерции для управления товарами и заказами, в социальных сетях для хранения и обмена информацией о пользователях, а также в медицинской сфере для управления медицинскими данными и историей пациентов. Распределенные системы позволяют обеспечить высокую эффективность и надежность хранения данных в таких критически важных областях.
Таким образом, архитектура распределенной системы является ключевым элементом ее функционирования. Она обеспечивает эффективное распределение данных, масштабируемость и надежность хранения информации. Распределенные системы нашли широкое применение в различных областях, где высокая эффективность и надежность являются критически важными требованиями.
Эффективность распределенных систем
Распределенные системы хранения данных предоставляют мощный инструмент для эффективной работы с большим объемом информации, распределенного на разных серверах. Это позволяет снизить нагрузку на отдельные серверы, распределяя данные между ними и обеспечивая более быстрый доступ к информации.
Одним из ключевых факторов эффективности распределенных систем является параллельная обработка данных. В то время как в традиционных системах обработка данных происходит последовательно, в распределенных системах обработка может происходить одновременно на нескольких серверах. Это существенно увеличивает скорость обработки данных и снижает время отклика системы.
Еще одним важным аспектом эффективности распределенных систем является их масштабируемость. Масштабируемость позволяет системе эффективно работать с увеличением количества данных и нагрузки. Когда в систему добавляются новые серверы, данные автоматически распределяются между ними, что позволяет сохранять высокую производительность и эффективность работы системы.
Также распределенные системы хранения данных обладают высокой отказоустойчивостью. При отказе одного сервера, данные автоматически переносятся на другие сервера, что предотвращает потерю информации и обеспечивает непрерывность работы системы. Это особенно важно в случае хранения критически важных данных, например, финансовой информации или медицинских записей.
Таким образом, эффективность распределенных систем хранения данных заключается в их способности обрабатывать данные параллельно, масштабироваться с ростом объема информации и обеспечивать высокую отказоустойчивость. Это позволяет эффективно работать с большим объемом данных, снижая нагрузку на отдельные серверы и обеспечивая быстрый и надежный доступ к информации.
Надежность хранения данных
Распределенные системы обладают разными методами обеспечения надежности хранения данных. Один из таких методов - репликация данных. При репликации данные копируются на несколько узлов, что позволяет обеспечить их доступность и целостность даже в случае отказа одного или нескольких узлов. Таким образом, распределенная система может продолжать работать, не прерывая обработку запросов пользователей.
Разделение данных
Надежность хранения данных также достигается благодаря разделению данных на несколько узлов. При этом каждый узел хранит только часть данных, что позволяет более эффективно использовать ресурсы системы. В случае отказа одного или нескольких узлов, данная система продолжает функционировать, так как данные могут быть восстановлены из других узлов.
Кроме того, разделение данных позволяет более равномерно распределить нагрузку на узлы системы, что повышает ее производительность и отказоустойчивость. Если один узел недоступен или перегружен, другие узлы могут продолжить обработку запросов и обеспечить доступность данных.
Резервирование данных
Для обеспечения надежности хранения данных распределенные системы также используют резервирование данных. Это означает, что помимо основных копий данных на узлах, имеются еще дополнительные резервные копии, которые могут быть использованы для быстрого восстановления данных в случае их потери.
Это мероприятие позволяет минимизировать потери данных и уменьшить время простоя системы при сбоях. Благодаря резервированию данных, распределенные системы могут обеспечивать высокую доступность данных и минимальное время восстановления в случае сбоев.
Таким образом, надежность хранения данных в распределенных системах достигается за счет использования репликации, разделения данных и резервирования данных. Эти методы позволяют обеспечить высокую доступность данных, сохранить их целостность и обеспечить быстрое восстановление в случае сбоев. Распределенные системы являются надежными и масштабируемыми решениями для хранения и обработки больших объемов данных.
Масштабируемость системы
Масштабируемость системы достигается за счет добавления новых узлов или увеличения ресурсов существующих узлов. Распределенные системы хранения данных позволяют горизонтальное масштабирование, при котором данные разделяются между несколькими узлами, что позволяет увеличить общую производительность и обеспечить отказоустойчивость системы.
Важным аспектом масштабируемости является возможность автоматического масштабирования системы в зависимости от нагрузки. Это позволяет системе гибко и эффективно адаптироваться к изменяющимся потребностям пользователей и обеспечить высокую доступность данных.
Горизонтальное масштабирование
Горизонтальное масштабирование позволяет распределить данные между несколькими узлами, что позволяет достичь высокой производительности и отказоустойчивости системы. При горизонтальном масштабировании добавление новых узлов позволяет увеличить общую производительность системы без необходимости переноса или изменения структуры данных.
Однако, при горизонтальном масштабировании необходимо учитывать некоторые аспекты, такие как согласованность данных, балансировка нагрузки, и обмен данными между узлами. Распределение данных должно быть организовано таким образом, чтобы минимизировать задержки и обеспечить эффективную работу системы.
Вертикальное масштабирование
Вертикальное масштабирование представляет собой увеличение ресурсов (процессоров, памяти) существующих узлов. Этот подход позволяет увеличить производительность системы без необходимости изменения ее архитектуры и распределения данных.
Однако, вертикальное масштабирование имеет свои ограничения. На практике существует предел, до которого можно увеличить ресурсы узлов. Кроме того, вертикальное масштабирование может быть более затратным и сложным в реализации по сравнению с горизонтальным масштабированием.
В идеальном случае, система должна обеспечивать возможность комбинированного масштабирования - как горизонтального, так и вертикального. Это позволит максимально эффективно управлять ресурсами и обеспечивать высокую производительность и доступность системы.
Масштабируемость системы является ключевым аспектом при разработке распределенных систем хранения данных. Горизонтальное и вертикальное масштабирование позволяют эффективно управлять ресурсами и достичь высокой производительности и надежности системы. Значительные объемы данных в современном информационном обществе требуют масштабируемости системы для обеспечения эффективной работы и удовлетворения потребностей пользователей.
Применение распределенных систем
Распределенные системы хранения данных имеют широкий спектр применения и могут быть использованы во многих областях, где требуется эффективное и надежное хранение информации.
1. Облачные сервисы
Одним из главных применений распределенных систем является облачное хранение данных. Благодаря таким сервисам, как Amazon S3, Microsoft Azure и Google Cloud Storage, пользователи могут сохранять и получать доступ к своим данным из любого места и с любого устройства.
2. Большие данные и аналитика
Распределенные системы хранения данных используются для обработки и анализа больших объемов данных. Такие системы, как Apache Hadoop и Apache Spark, позволяют распределенно выполнять вычисления над большими наборами данных, что ускоряет процесс аналитики и обеспечивает более быстрый доступ к результатам.
Это особенно полезно для компаний, которые работают с большими объемами данных, например, в области финансов, медицины или телекоммуникаций.
3. Интернет вещей
Распределенные системы также активно применяются в сфере интернета вещей. Благодаря этим системам, устройства могут обмениваться данными между собой и с центральным сервером, что позволяет создавать интеллектуальные системы управления и мониторинга.
Например, умные дома, оснащенные различными датчиками, могут использовать распределенные системы для управления освещением, отоплением и другими устройствами, а также для сбора и анализа данных о потреблении электроэнергии или состоянии системы безопасности.
Применение распределенных систем хранения данных в различных сферах позволяет улучшить эффективность работы, обеспечить надежность хранения информации и расширить возможности аналитики больших объемов данных.
Видео:
Лекция 4 | Распределенные системы хранения и обработки данных | Владислав Белогрудов

 Керамическая плитка lasselsberger разработана с учетом высоких требований к износостойкости и безопасности общественных пространств. Поверхности выдерживают интенсивную нагрузку, сохраняют внешний вид при многолетней эксплуатации и устойчивы к влаге, химическим реагентам и механическим повреждениям.
Керамическая плитка lasselsberger разработана с учетом высоких требований к износостойкости и безопасности общественных пространств. Поверхности выдерживают интенсивную нагрузку, сохраняют внешний вид при многолетней эксплуатации и устойчивы к влаге, химическим реагентам и механическим повреждениям. Современный промышленный сектор переживает масштабную трансформацию. Цифровизация, автоматизация и внедрение интеллектуальных систем становятся обязательными факторами конкурентоспособности. Сегодня под термином «умная промышленная техника» подразумеваются не только производственные роботы, но и целый комплекс решений: от сенсорных систем до автономных транспортных средств. Технологии позволяют сократить ручной труд, повысить точность операций и снизить затраты на обслуживание.
Современный промышленный сектор переживает масштабную трансформацию. Цифровизация, автоматизация и внедрение интеллектуальных систем становятся обязательными факторами конкурентоспособности. Сегодня под термином «умная промышленная техника» подразумеваются не только производственные роботы, но и целый комплекс решений: от сенсорных систем до автономных транспортных средств. Технологии позволяют сократить ручной труд, повысить точность операций и снизить затраты на обслуживание. Морские контейнеры стали неотъемлемой частью современной логистики, строительства и хранения. Они универсальны, долговечны и идеально подходят для различных задач. В Москве и Московской области аренда и продажа таких контейнеров пользуется стабильным спросом, что связано с развитием бизнеса и необходимостью временных или постоянных решений для хранения грузов.
Морские контейнеры стали неотъемлемой частью современной логистики, строительства и хранения. Они универсальны, долговечны и идеально подходят для различных задач. В Москве и Московской области аренда и продажа таких контейнеров пользуется стабильным спросом, что связано с развитием бизнеса и необходимостью временных или постоянных решений для хранения грузов.